Might some of the problems in applying data protection law to machine learning arise because we’re using too simple a model? Sometimes an over-simplified model can be hard to apply in practice. So here’s a model that’s a bit more complex but, I hope, a lot easier to apply. It’s also a lot more informative, especially about what data we should be using, about what people, and for how long.
This views a machine learning model as having four stages:
- Development, where we decide which features are of interest, which algorithms to use, etc.;
- Learning, where algorithms decide what weights to give to each feature;
- Use, where we apply the model to real data and situations;
- Review, where we consider how well the model worked.
These form a cycle: review may trigger a new round of development, learning, etc. There may also be shorter cycles within the loop – iterating between development and learning when we discover that we chose the wrong features or algorithms, for example – but I haven’t shown those in the diagram.
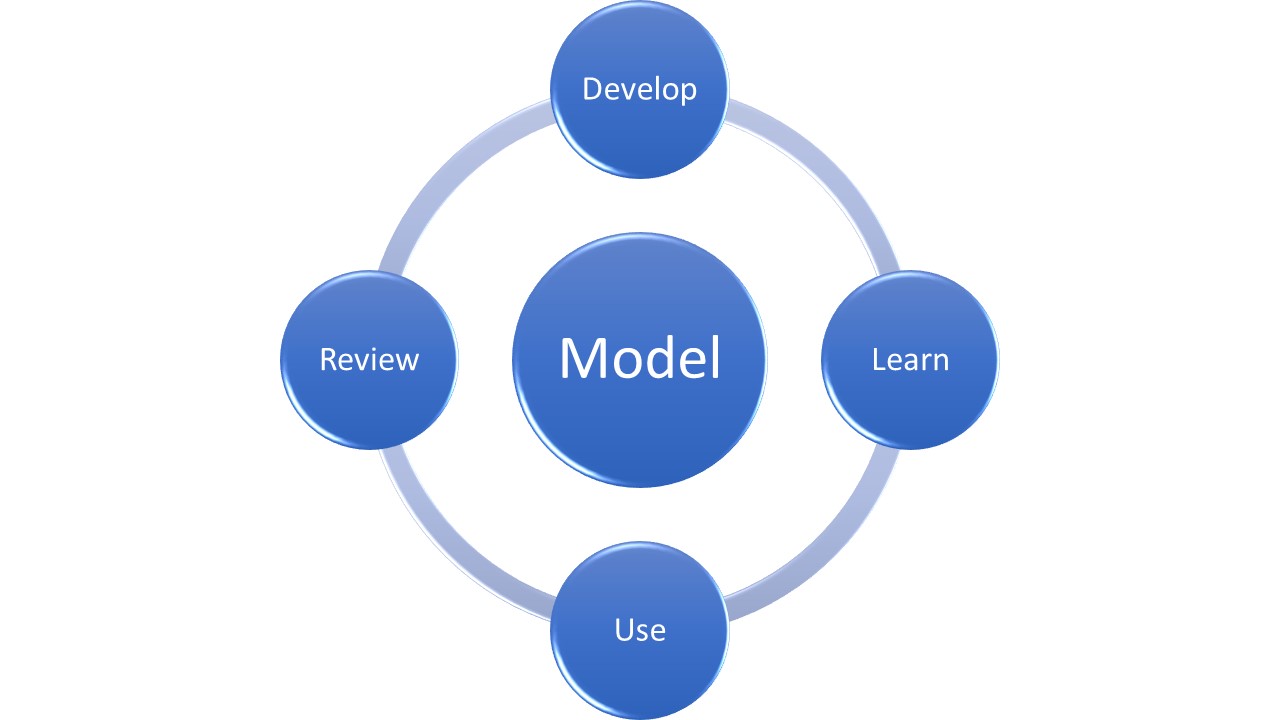
Each stage has different requirements for the data it uses, so they should be considered separately under data protection law (that law definitely applies if machine is learning about people, though the same model seems to work well even if it isn’t). In particular, this approach suggests there may be a nice balance between the quantity of data required at each stage and the safeguards that can be applied: stages that need more data may also be able to apply more safeguards.
Note that, at a higher level, the ICO has new Guidance on AI and Data Protection, covering Governance, Accountability, Lawfulness, Fairness, Transparency, Security, Data Minimisation and Individual Rights.
Development/Feature Selection
This stage needs a broader selection of data than any of the others, precisely because one of its roles is to identify and eliminate fields and sources that don’t provide sufficient useful information for the model’s purpose. Here, we need a representative set of data, but it may be acceptable for those data to be less than comprehensive, so long as they include the features likely to be relevant, and a representative range of subjects. It should be possible to use pseudonymised data for feature selection, and there should be no need to keep the data after the model has been constructed.
A wide range of GDPR lawful bases could be used for this stage: in education the most likely are probably Necessary for Contract (if the model is part of the contracted service), Necessary for Public Task, Necessary for Legitimate Interests, and Consent (provided we ensure the resulting data are still representative). If the institution already has the required data for some other “necessary for…” purpose then the “statistical” provisions may be worth considering since these provide helpful guidance on how to maintain separation between the purposes and avoid creating risks to individuals.
Learning
This stage uses the reduced set of fields identified in the Development stage, but it is essential that the data in those fields be comprehensive and unbiased. To reduce the risk of learning discovering proxies for protected characteristics (typically, those covered by discrimination law), we may need to include data about those protected characteristics at the learning stage. Again, it should be possible to use pseudonymised data for Learning, and it should not be necessary to keep the data after the model has been constructed.
Here, Consent is less likely to be an appropriate basis, because opt-in data is likely to result in models that recognise those who opt-in. Again, the statistical provisions are informative.
Use
Here we apply the model to real people and situations, usually with the aim of providing them with some kind of personalised response. We probably need all the fields that were identified in the Development stage, though Learning may have identified some that are less important (or are correlated with others) so can be eliminated. The model should, at least, recognise data records that are too sparse to be reliably usable. Here the data does need to allow identification of, or personalisation to, an individual, so pseudonyms are unlikely to work. But allowing individuals to self-select whether, or when, the model is applied to them is much less of a problem. And tight time-limits on how long we keep data should be possible.
Here Consent and Necessary for Contract are the most likely lawful bases; Necessary for Public Task or Legitimate Interests are possible, though we need to consider the risk of applying the model to those who have not actively engaged; statistical, which prohibits individual impact, is not.
Review
Finally the Review stage will need to include historical data – what actually happened – and may need additional information about outcomes that was not relevant to the Use stage. It should be possible, however, to protect this wider range and duration of data by either pseudonymisation or anonymisation.
The review stage is likely to process some data on the basis of Consent (from individuals who are either particularly happy or unhappy with their treatment). However this must be balanced with a representative selection of data from those who do not respond. Sampling should be possible, even desirable, as a safeguard. It may be necessary to use Consent for this as well (for example if the only way to discover outcomes is through self-reporting), but if the institution already has the data needed for Review then Necessary for Public Task or Legitimate Interests may be more appropriate ways to achieve the required representativeness.
Summary
The following table shows how this might work…
| Stage | Who | What | How long | Safeguards | Main legal bases |
| Develop | Representative of the population | Potentially relevant to the model’s purpose (largest set) | Till model built | Pseudonym/
Anonymous |
Contract,
Statistics, Public task, Legitimate interest, Consent |
| Learn | Comprehensive coverage of affected population | Relevant (as identified by Develop). May also need to check discrimination | Till model built | Pseudonym/
anonymous |
Contract,
Statistics, Public task, Legitimate interest |
| Use | Voluntary, either as part of a contracted service or by specific consent | Informative (may be less than Learn if model can cope with null entries) | During (individual) use | Identifying | Consent, Contract |
| Review | Sampled, to ensure a representative set | Relevant. May also need to check outcomes. | Historical | Pseudonym/ anonymous | Legitimate Interest, Public Task, Consent |